django+nginx+mysql 三容器部署

前言
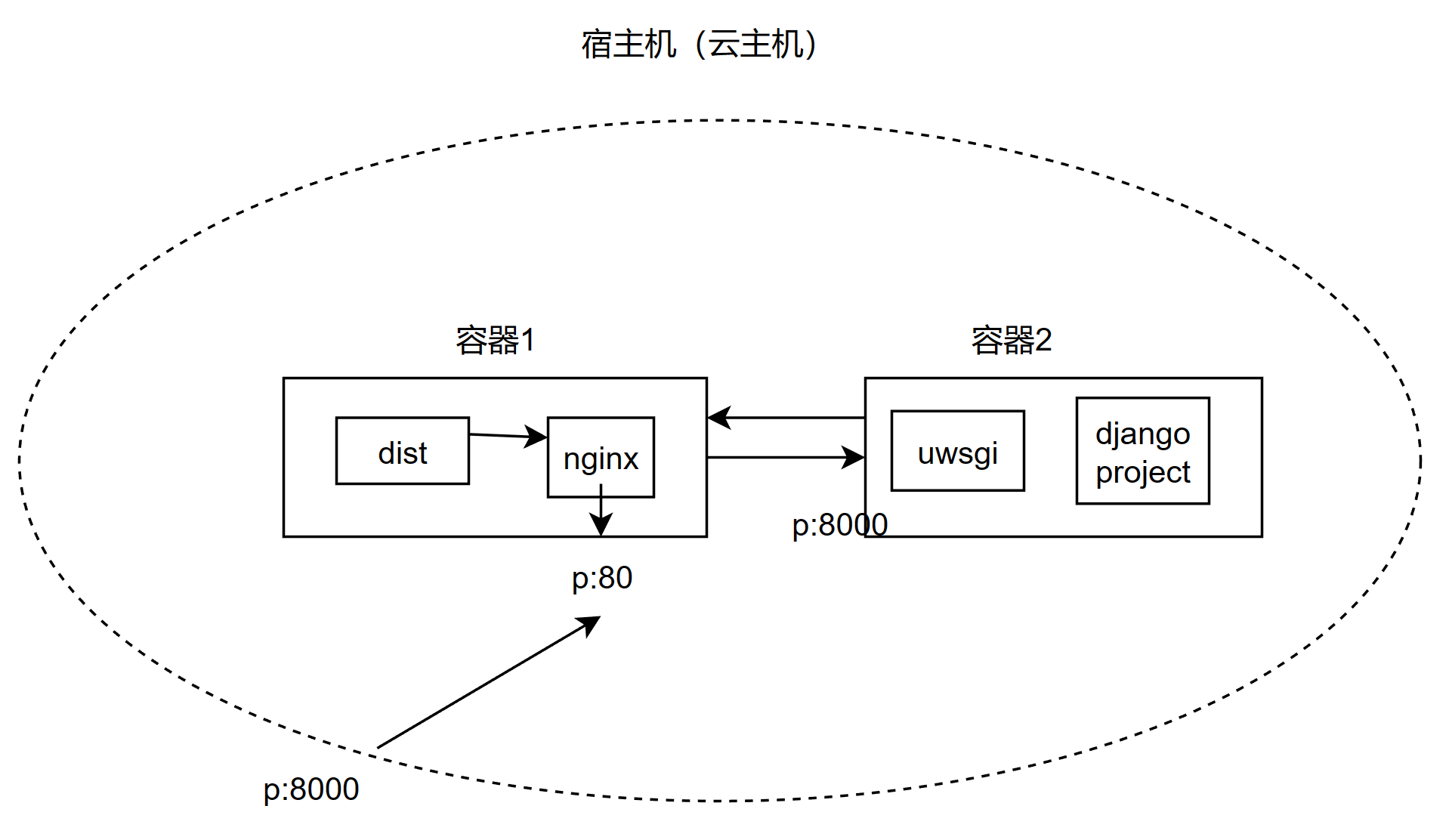
之前的部署直接采用默认的 sqlite3 作为数据库。因为 sqlite3 是文件式数据库,所以打造容器时,本地调试过程中的数据记录也被包含进去。另外,生产环境中,不可能使用 sqlite。因此,在之前的 django+nginx 的基础上,引入了 mysql 容器。
镜像设置
首先在根目录创建一个MySQL数据库,下面有 data.sql 和 Dockerfile。这里我们先单独启动一下 mydql 容器。这时候 mysql 容器里已经有 django 的数据库了(database)。这是因为 data.sql 已经提前创建好了数据库并设置为当前数据库:
CREATE DATABASE IF NOT EXISTS my_database;
USE my_database;
而 Dockerfile 的内容为:
FROM mysql:8
ENV MYSQL_ROOT_PASSWORD pass
COPY ./data.sql /docker-entrypoint-initdb.d/data.sql
最后一行使得 data.sql 在容器初始化时就被执行。这时候虽然有了数据库但是没有表格,需要去 django 项目下,执行python manage.py migrate来在库里面创建表格。运行docker exec -it <name> /bin/bash,进入容器 terminal,进入 mysql 命令行,show tables,可以得到:
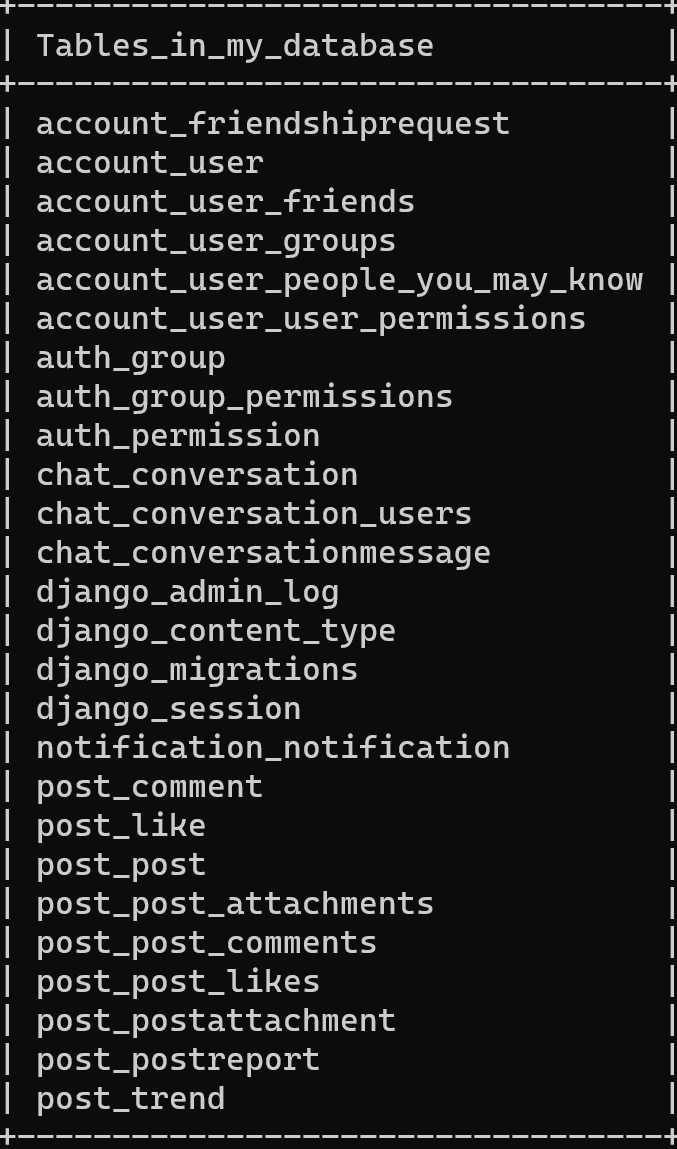
说明,数据表格创建成功了。
django settings.py 变动
由于之前是默认的 sqlite3,配置非常简单,只需要指定数据库文件位置。在 django 的 settings.py 中,关于 mysql 数据库的设定为:
DATABASES = {
'default': {
'ENGINE': 'django.db.backends.mysql',
'NAME': 'my_database',
'HOST': 'database', #compose中mysql容器的服务名称
'PORT': '3306',
'USER': 'root',
'PASSWORD': 'pass',
'OPTIONS': {
'init_command': "SET sql_mode='STRICT_TRANS_TABLES'"
},
}
}
docker-compose
由于我们是全 docker 运行,因此也要实验一下将 django 项目打包成 docker 容器后,能否也能与 mysql 容器通信且成功创建表格。这次用 compose 实现。
version: "3.9"
services:
nginx:
build: ./wey-frontend/
restart: always
ports:
- "8000:80"
volumes:
- web_static:/var/www/mysite/assets/static
- web_media:/var/www/mysite/assets/media
depends_on:
- django
django:
build: ./wey_backend/
restart: always
expose:
- 8000
command: >
sh -c "python manage.py collectstatic --noinput
&& python manage.py migrate
&& uwsgi --ini uwsgi.ini"
volumes:
- web_static:/var/www/mysite/assets/static
- web_media:/var/www/mysite/assets/media
depends_on:
- database
database:
build: ./MySQL/
ports:
- '3306:3306'
# environment:
# MYSQL_DATABASE: 'appdb'
# MYSQL_PASSWORD: 'root'
# MYSQL_ROOT_PASSWORD: 'root'
# volumes:
# - 'db:/var/lib/mysql'
# # command: ['mysqld', '--character-set-server=utf8mb4', '--collation-server=utf8mb4_unicode_ci']
volumes:
web_static:
web_media:
总结
用 mysql 作为数据库,更符合实际生产场景。由于一开始 mysql 容器内没有数据库,因此需要在 Dockerfile 中创建自定义数据库并且使用。django 的 settings.py 中也要作相应调��整。docker-compose 中,需要在创建 django 容器后,执行python manage.py migrate,来迁移数据库(即在自定义数据库中创建表来供上线后数据放置)。