实习过程中,大量使用 git。放假前,同事提出,我提交的版本覆盖了他的。为了能在节后解决问题,顺便对 git 工具体系做一个彻底的复习,写下此文。
初始化
git 是一种分布式管理工具。它能实现多人共同维护一个工程文件。下载好 git,并配置好身份信息后,可以有两种方式开始 git: 一种是下载 git 仓库,一种是在本地执行 git init 。这两种方式执行后,文件夹里都会有一个 .git 文件夹。
git config 相关命令配置仓库,这篇文章介绍得很详细了。总体来说,git 配置分为三个层次:仓库级(local)、用户级(global)、系统级(system)。配置的优先级是仓库->用户->系统。git config -l可以将当前仓库的所有可用配置列举出来,如下:
diff.astextplain.textconv=astextplain
filter.lfs.clean=git-lfs clean -- %f
filter.lfs.smudge=git-lfs smudge -- %f
filter.lfs.process=git-lfs filter-process
filter.lfs.required=true
http.sslbackend=openssl
http.sslcainfo=C:/Program Files/Git/mingw64/ssl/certs/ca-bundle.crt
core.autocrlf=true
core.fscache=true
core.symlinks=false
pull.rebase=false
credential.helper=manager-core
credential.https://dev.azure.com.usehttppath=true
init.defaultbranch=master
filter.lfs.clean=git-lfs clean -- %f
filter.lfs.smudge=git-lfs smudge -- %f
filter.lfs.process=git-lfs filter-process
filter.lfs.required=true
user.name=li199-code
user.email=
http.sslverify=false
credential.http://git.zhi-shan.cn.provider=generic
credential.https://gitee.com.provider=generic
core.repositoryformatversion=0
core.filemode=false
core.bare=false
core.logallrefupdates=true
core.symlinks=false
core.ignorecase=true
remote.origin.url=http..
remote.origin.fetch=+refs/heads/*:refs/remotes/origin/*
branch.master.remote=origin
branch.master.merge=refs/heads/master
user.name=
user.email=
我现在有一个需求,要修改提交时的姓名和邮件:
git config --local --add user.name jason
git config --local --add user.email [email protected]
git 提交
可以理解有两种提交:一种提交到本地的 git 区,一种是在本地提交后,提交到远程仓库,即 push。
git status查看本地有哪些修改。git log查看提交日志。git checkout [hashcode]根据某次提交的哈希值将代码回滚。
有一个有用的 git log 命令:git log --graph --oneline. 可以用查看历史提交的记录。
branch 分支(时间线)
git branch [name]创建分支。新分支会继承主分支上的所有历史改动,类似于时间线的概念。
一般来说,其他分支是在主分支基础上的重大更新,如果要合并其他分支,需要在切换到主分支后,执行 git merge [name].
git checkout
git checkout [id] filepath 用于回滚时,最好加上要回滚的文件名,这样只会改变该文件,而不会专门进入 detached head 模式。
"Detached HEAD"是一个 Git 术语,用来描述 HEAD 指针在一个特定的提交版本上,而不是指向任何分支的状态。这种状态下,你处于一个游离的、临时的工作环境,没有与之关联的分支。
当你切换到一个特定的提交版本(通过提交哈希、标签或分支名)而不是一个分支时,Git 会将 HEAD 指针直接指向该提交。这就是所谓的"Detached HEAD"状态。
Detached HEAD 状态通常用于以下情况:
查看历史提交:你可以在 Detached HEAD 状态下查看、比较和分析以前的提交。这对于浏览代码历史、调试问题或查找特定更改非常有用。
临时工作:如果你想在不影响当前分支的情况下进行一些临时的更改或实验,可以切换到 Detached HEAD 状态。你可以在该状态下创建新的提交,但这些提交不会属于任何分支。
git remote
以上说的操作都是在本地完成的。如何将本地改好的代码,传到云端完成多人协同开发呢?
如果是本地初始化 git,在 git push 之前,需要配置文章仓库的 url:
git remote add <name> <url>
<name>是 url 的别名,毕竟 url 很长。默认为 origin。同时,本地 git 文件夹里的 ref 下,也会创建 origin 文件夹,存缓存数据。
vscode git 工作流
首先,正确的工作流是:add -> commit -> pull -> push。在 vscode 中,commit -> pull -> push 简化为一个按钮:commit & sync.
git 状态(更新)
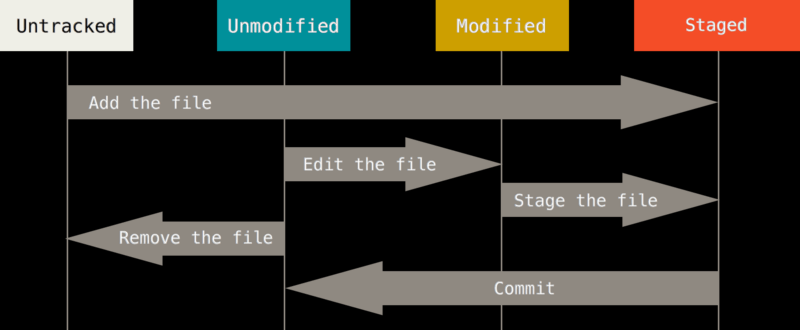
这张图展示了 git 的四种状态:untracked, unmodified, modified, staged. 从指向每个状态的箭头,我解读出一些有用的信息。首先,git init命令执行,创建了一个“容器”,但是所有的文件依旧是 untracked. staged 要么是从 untracked 转来,要么是已经被跟踪的文件被修改后执行git add而来。stage 状态的文件被 commit 后,状态就会回到 unmodified。
在现代的工作环境下,大多数人是通过 vscode 等 IDE 进行 git 操作了。所以,结合 vscode 页面说明对应的 git 状态和操作有助于加深理解。以我的 vscode 界面为例。如果一个项目还没有被 git 管理,这时候初始化,那么在 vscode 的 explorer 里,所有文件都会变成绿色,这种对应的就是上图的 untracked 状态,绿色的 U。同理新建一个文件,也是这种状态。然后,如果修改了一个文件,modified,黄色的 M。删除不在上面的图中,表示为红色的 D。当然了,没有修改的文件就是白色的,unmodified。
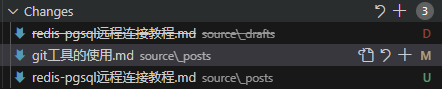
继续看,只有�处在 staged 状态的文件才能被 commit。所以下图的加号就是把 modified 变为 staged,点了之后,文件会进入 staged changes。这里都是为了精细化控制单个文件。另外,vscode 有自己一套默认规则。正常情况下,点 commit 按钮只会提交 staged changes 内容,如果只有 changes 没有 staged changes,那么 vscode 就会自动将 changes 内容变为 staged 并提交。

其他问题
为什么实习连的公司内部 gitlab 仓库,不用像 github 那样配置 ssh?
因为 git 远程仓库有两种方式,ssh 登录和 https 登录,而我是通过输入账号密码登录的,属于后者。且 windows credential helper 帮我记下了 git 仓库的账号和密码(一台主机可以储存多种仓库的账号,比如 github,gitlab),避免每次提交代码需要重复输入。
git 学习资源
可视化学习





