python机器学习-数据降维

PCA(主成分分析)
example:
import numpy as np
from sklearn.decomposition import PCA
# 创建一个示例数据集
data = np.array([
[1.5, 2.0, 3.0, 4.5],
[2.2, 2.8, 3.9, 4.2],
[1.9, 2.5, 3.2, 4.7],
[2.7, 3.0, 3.6, 4.0],
[2.3, 2.9, 3.7, 4.3]
])
# 初始化 PCA 模型,指定主成分的数量
pca = PCA(n_components=2)
# 对数据进行拟合
pca.fit(data)
# 获取主成分
principal_components = pca.components_
# 获取主成分的方差贡献比例
explained_variance_ratio = pca.explained_variance_ratio_
# 对数据进行 PCA 转换
transformed_data = pca.transform(data)
print("原始数据:\n", data)
print("主成分:\n", principal_components)
print("主成分的方差贡献比例:", explained_variance_ratio)
print("PCA 转换后的数据:\n", transformed_data)
输出:
原始数据:
[[1.5 2. 3. 4.5]
[2.2 2.8 3.9 4.2]
[1.9 2.5 3.2 4.7]
[2.7 3. 3.6 4. ]
[2.3 2.9 3.7 4.3]]
主成分:
[[-0.61305201 -0.55633419 -0.46392272 0.31533349]
[-0.53989171 -0.03347232 0.83292811 0.11673604]]
主成分的方差贡献比例: [0.87919714 0.0703791 ]
PCA 转换后的数据:
[[ 1.00928239 -0.02497259]
[-0.37705186 0.28493986]
[ 0.45617665 -0.0677326 ]
[-0.71873459 -0.2649261 ]
[-0.36967259 0.07269143]]
在深入之前,有必要解释一下 PCA 为什么在高维数据中找最大方差的方向而不是别的指标(比如最大值),来降维的?找到最大方差的方向意味着在这个方��向上数据的变化最为显著,即信息越丰富。以我之前接触到的人脸图像为例,不同位置的像素有差异,才能让分类器有能力识别。
为了将我视频学习到的和这个例子对应起来,将输出中的几个部分进行解释:
首先,这个例子中的原始数据是有五个样本,每个样本有四个维度的特征(一开始我还真没搞明白这个)。然后,pca 算法找出四个主成分(找的过程是通过计算协方差矩阵和特征向量等步骤得来的,视频举的例子是几何平面便于理解,而书上的公式是一种通用的方法,适合任意数量纬度特征,二者本质相同),也就是输出中的主成分。主成分本质上是一个方向向量,且模为 1,所以本例中的主成分有两组,每组四个值,对应四种特征,哪个特征的绝对值最大,说明哪个特征在这个主成分中占主导。方差贡献比例就是,依次计算所有数据在某一主成分上的投影点到距离之和,然后全部求和,最后计算一个主成分所占的比例,比例越高,说明方差越大,数据在这个主成分上差异越明显。最后的转换后数据,则是将所有数据在某一主成分上的投影点到距离,作为以各主成分为新坐标轴的空间内的坐标。
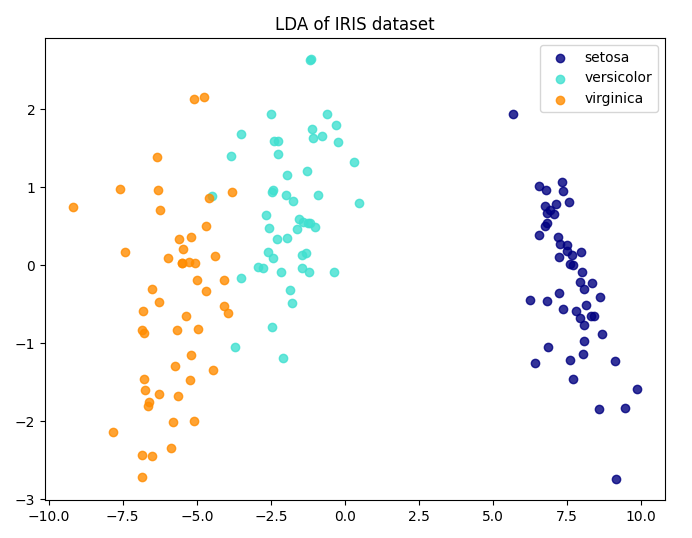
LDA(线性判别分析)
不同于 PCA,LDA 有类别标签参与训练,所以是有监督的。LDA 训练过程中的优化目标也变成了最大化不同类之间的类间差距,而不是 PCA 的找样本内方差最大的方向,可以说是完全不同的方法,但是都能实现降维。
LDA 在一条线上投影数据点,并且让投影点的不同类之间的均值差距最大,而同类的方差最小,这样就让不同类之间的类间差距最大化。
可以说,LDA 的适用范围更窄些,它要求数据有明确的标签,且只适用分类问题;而 PCA 则适用范围更广,因为它只要求提供特征,能适用于不限于分类的问题。
example:
# 导入必要的库
from sklearn import datasets
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis
import matplotlib.pyplot as plt
# 加载示例数据集(这里以Iris数据集为例)
iris = datasets.load_iris()
X = iris.data
y = iris.target
# 创建LDA模型
lda = LinearDiscriminantAnalysis(n_components=2) # 我们希望将数据降至二维
# 拟合模型并进行降维
X_lda = lda.fit_transform(X, y)
# 绘制降维后的数据
plt.figure(figsize=(8, 6))
colors = ['navy', 'turquoise', 'darkorange']
lw = 2
for color, i, target_name in zip(colors, [0, 1, 2], iris.target_names):
plt.scatter(X_lda[y == i, 0], X_lda[y == i, 1], alpha=0.8, color=color,
label=target_name)
plt.legend(loc='best', shadow=False, scatterpoints=1)
plt.title('LDA of IRIS dataset')
plt.show()