《python机器学习》分类算法
· 阅读需 3 分钟

前言
我打算开一个全新的系列,记录我在学习《python 机器学习》这本书过程中的要点和感想。
决策边界图
分类任务中的一种图,可以看出模型在整个网格内的预测结果。
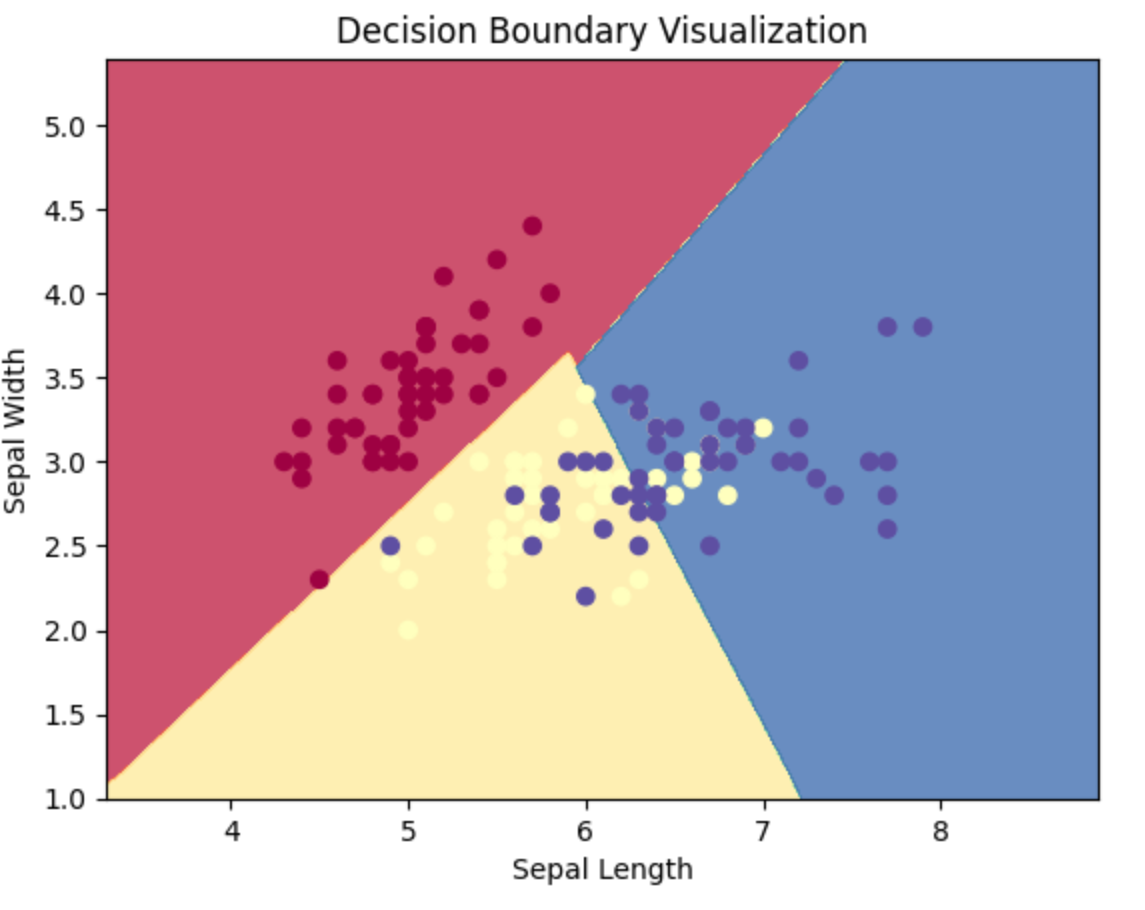
代码如下:
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.svm import SVC
# 步骤2:加载鸢尾花数据集
iris = datasets.load_iris()
X = iris.data[:, :2] # 使用前两个特征以便进行可视化
y = iris.target
# 步骤3:训练一个SVM分类器
clf = SVC(kernel='linear')
clf.fit(X, y)
# 步骤4:创建一个网格来覆盖特征空间
x_min, x_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, 0.01), np.arange(y_min, y_max, 0.01))
# 步骤5:对网格上的每个点使用分类器进行预测,获取决策边界
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
# 步骤6:可视化数据点、决策边界和决策区域
plt.contourf(xx, yy, Z, cmap=plt.cm.Spectral, alpha=0.8)
plt.scatter(X[:, 0], X[:, 1], c=y, cmap=plt.cm.Spectral)
plt.xlabel('Sepal Length')
plt.ylabel('Sepal Width')
plt.title('Decision Boundary Visualization')
plt.show()
主要的函数有 meshgrid,功能是生成网格坐标数据。还有 contourf,绘制决策边界图。
逻辑回归
线性计算方式,激活函数采用 sigmoid,从而得出属于正类别的概率。
决策树/随机森林
决策树就是一种二叉树,通过计算一种特征能否尽可能的将类别区分来决定选择哪一种特征作为节点。随机森林则是决策树的集合,通过随机抽样得到训练样本来引入随机性,并且最后由多数投票来确定预测结果。