sklearn crash course

前言
油管视频教程。想到哪儿写到哪儿。
如何让 jupyter notebook 切换到 venv 环境
首先在虚拟环境下的 cmd 中运行:
pip install ipykernel
然后,在在虚环境中将当前的虚拟环境添加到 Jupyter Notebook 的 kernel 中:
python -m ipykernel install --name 虚环境名称 --display-name 虚环境名称 --user
框架
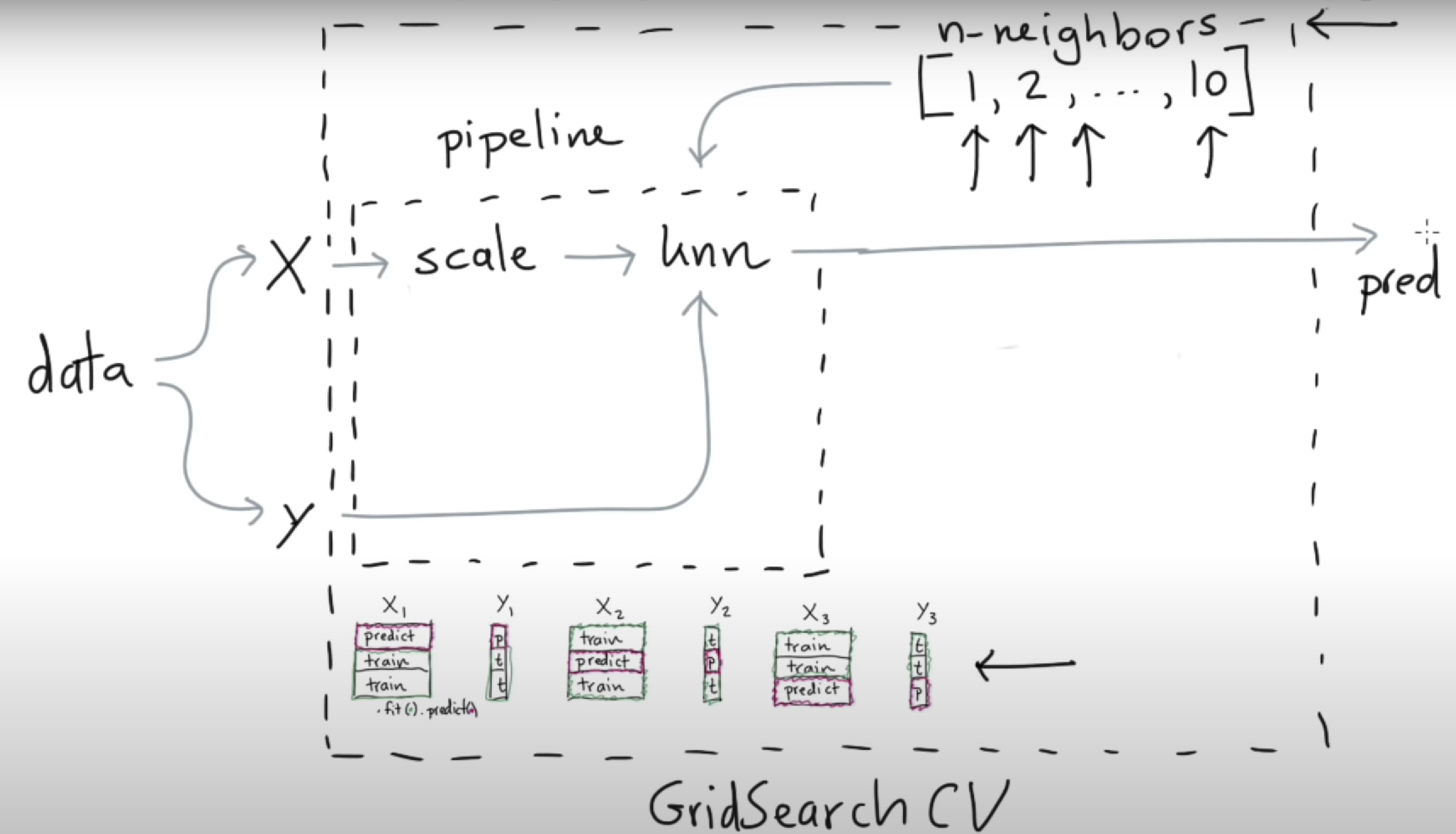
上图是用 sklearn 完成机器学习任务的一般框架。首先数据类型分为特征(X)和标签(y)。pipeline(管道、流程)包含数据归一化(preprocessing 的一种)和模型(model)。pipeline 有两个重要 api:fit 和 predict,前者训练,后者测试。
如果要确定超参数的值,且训练数据有限的情况下,需要用交叉验证(Cross validation, CV)。用法是:
mod = GridSearchCV(estimator=pipe, param_grid={
'model__n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
},
cv=3)
其中,estimator 是 pipeline 或者 model,param_grid 是需要确定的超参数,是一个字典,键是'model__[name]'的格式,cv 表示要将数据分为几折来进行交叉验证。
完整代码如下:
from sklearn.datasets import load_boston
from sklearn.neighbors import KNeighborsRegressor
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.model_selection import GridSearchCV
import pandas as pd
mod = GridSearchCV(estimator=pipe, param_grid={
'model__n_neighbors': [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
},
cv=3)
mod.fit(X, y);
## 查看交叉验证的结果
pd.DataFrame(mod.cv_results_)
预处理
视频以一个存在离群点的场景为例,说明预处理措施的作用。离群点会导致模型预测的偏差。
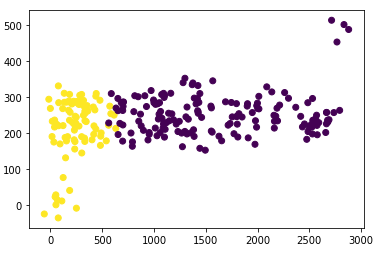
最容易想到的预处理方式是正态分布化,但是离群点问题仍然存在。因此,采用一种均匀分布方法:QuantileTransformer。
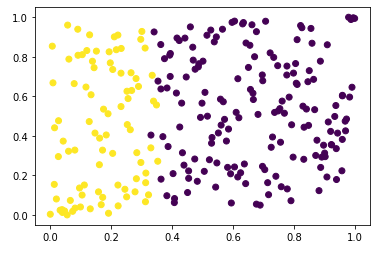
可以看出,离群点不明显了。
另外,增加特征的维数(PolynomialFeatures)也在预处理范畴内。增加特征维数可以更好地捕获数据中的特征关系。
最后介绍了 One Hot Encoding,一种经典的将文本数据转为数值特征(标签)的预处理措施。
总结一下,sklearn 中,调用预处理措施的格式是:Transformer().fit_transform(data).
指标
precision_score:分母是模型预测为正类的个数,分子是模型预测正类正确的个数。
recall_score: 分母是样本中所有正类的个数,分子是分母中模型预测正类正确的个数。
GridSearchCV (或者 model 和 pipeline)可以使用 scoring 来自定义目标函数。而自定义的损失函数需要 make_scorer 生成。
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import precision_score, recall_score, make_scorer
def min_recall_precision(est, X, y_true, sample_weight=None):
y_pred = est.predict(X)
recall = recall_score(y_true, y_pred)
precision = precision_score(y_true, y_pred)
return min(recall, precision)
grid = GridSearchCV(
estimator=LogisticRegression(max_iter=1000),
param_grid={'class_weight': [{0: 1, 1: v} for v in np.linspace(1, 20, 30)]},
scoring={'precision': make_scorer(precision_score),
'recall': make_scorer(recall_score),
'min_both': min_recall_precision},
refit='min_both',
return_train_score=True,
cv=10,
n_jobs=-1
)